
はじめに
アメリカのSentinel Systemは1億人以上のClaims Dataを保持し、医薬品の安全性監視活動に貢献してきました。最近はSentinel System内のClaims Dataに電子カルテデータを統合し活用する取り組みに力をいれています。
本記事ではBroadening the reach of the FDA Sentinel system: A roadmap for integrating electronic health record data in a causal analysis framework1)という記事を参照し、その取組を紹介します。「安全性監視活動で電子カルテを活用するために必要なロードマップ」という観点から解説します。
Sentinel systemとは
Sentinel systemの概要
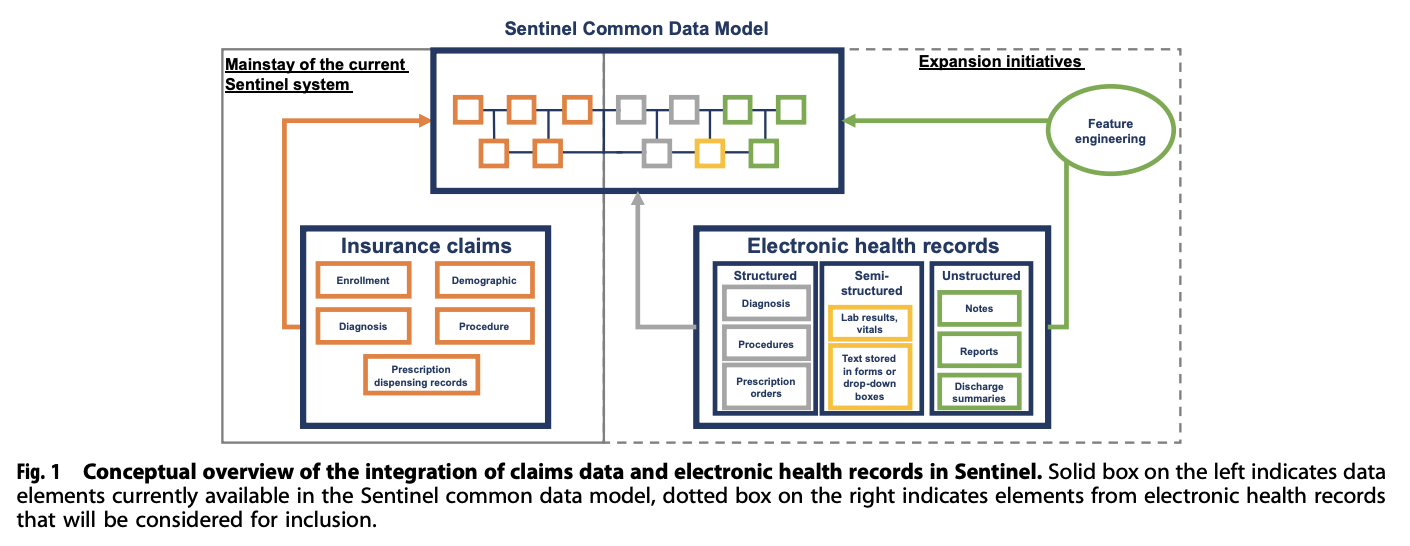
アメリカで承認された医薬品・医療機器の安全性モニタリングにデータベースを活用するプロジェクトとして、2008年にFDAがSentinel Initiativeというプロジェクトを開始しました。そのプロジェクトを通じてSentinel systemは、様々な保険者から収集したClaims DataをSentinel Common Data Modelに変換し、解析しやすいデータベースとして構築されました。
FDAが医薬品の安全性に関する課題を早期に検出したり、調査したりするための機能を強化しています。
図1: Conceptual overviw of the integration of claims data and electonic health records in Sentinel(引用1) のFigure1より画像を引用)
電子カルテデータを活用したい理由
Claims Dataだけだと、
- 測定したいアウトカムを取得できない
- 重要な交絡因子を取得できない
- 対象集団を抽出するためにアルゴリズムを構築しても、許容できる精度に達しない
といった限界があります。
そういった背景で、Claims Dataと電子カルテデータの統合が必要とされています。
安全性監視活動で電子カルテを活用するために必要なこと
安全性監視活動において、
- シグナルの検出
- シグナルの精査・評価
が必要とされ、それぞれの領域で、よりロバストな手法が求められています。
データベースを用いたシグナルの検出では、データマイニングを通じて、大量の結果(表のセル数)が生成されます。例えば、市販されている20,000の薬剤と17,000を超える有害事象で集計すると、3億を超える組み合わせ(セル)が生成されるのです。空欄のセルも多くスパースであることも特徴です。膨大な組み合わせについて適切にリスクを評価し、優先順位付けしながら各シグナルの精査・評価を行うことに大きな労力・難しさが伴います。
データソースとして電子カルテが追加された場合、複雑さがさらに増します。シグナル検出について、新たな手法・オペレーションとしてのフレームワークを確立させていく必要があります。
またシグナルの精査・評価プロセスにおいても、電子カルテデータを用いた因果分析のフレームワークが必要です。
フレームワークを確立させるために、下記3つのトピックに注力して、ロードマップを敷いています。
- 曝露前データにおける交絡調整及びサブグループの同定
- 曝露後データにおけるアウトカム同定方法
- 因果分析の方法論
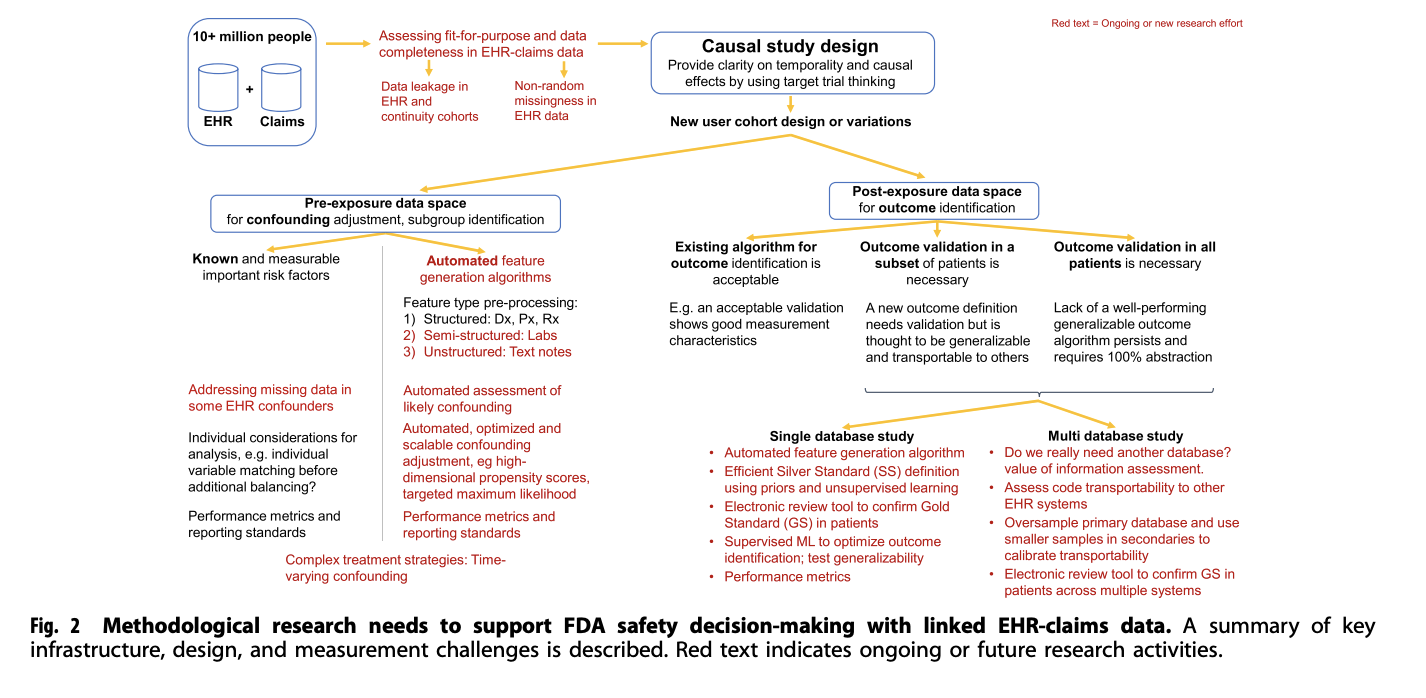
図1: Methodological research needs to support FDA safety decision-making with linked EHR-claims data(引用1) のFigure2より画像を引用)
本記事の後半では、いくつかに絞って紹介していきます。
特徴量エンジニアリング
先述した「曝露前データにおける交絡調整及びサブグループの同定」及び「曝露後データにおけるアウトカム同定方法」というトピックに関連して、特徴量エンジニアリングの手法が研究開発されています。
自然言語処理技術*1を用いた特徴量※2抽出の難しさ
電子カルテデータの特徴は構造データだけでなく、非構造データ(医師カルテ、放射線レポート、退院サマリ等)が存在していることです。非構造データを活用するために自然言語処理が必要です。その精度をあげるためには、領域や使用目的をかなり狭めた特化型自然言語処理アルゴリズムを構築する必要があります。
(※同じ心不全という疾患でも、救急科・循環器内科・心臓血管外科・クリニックでの慢性期管理では、診療内容や医師が記載するカルテの内容・用いる用語がかなり異なることが想像できると思います。抽出の精度をあげるためには、アルゴリズムの利用目的・状況に応じて個別カスタマイズが必要となります。)
アウトカム・交絡因子を含む全ての特徴量に対して特化型自然言語処理アルゴリズムを構築するのは、工数とメンテナンスの観点から非現実的です。
※1: 自然言語処理技術: 自然言語をコンピューターで分析する技術を指し、NLP(Natural Language Processing)とも呼ばれます。電子カルテ領域では、医師が自由記載したカルテ文章から副作用を抽出するといった目的で自然言語処理技術が利用されています。
※2: 特徴量: 対象の特徴を数値化したものです。本記事で取り扱われるアウトカム、交絡因子はいずれも特徴量に含まれます。
自然言語処理の活用方針
Sentinel Initiativeでは上手に優先順位付けを行っています。
- アウトカム抽出には領域に特化した自然言語処理を用いる
- 重要性高いので、工数をさいて特化型自然言語処理のアルゴリズム開発を行う
- 研究デザインによって、感度やPPV(Positive Predictive Value:陽性的中率)の調整が必要となる
- 交絡調整には領域横断的に使える汎用的な自然言語処理を用いる
- 様々な疾患領域の研究で同様の調整が行われることが多く、汎用的なアルゴリズムを流用できる
といった方針を打ち出しています。
また自然言語処理を用いた特徴量抽出においては、generalizability(母集団を代表するか)とtransportability(異なる集団にも当てはまるか)も重要で、それらを高めるための取り組み・研究も行っています。3)
因果分析の方法論
研究デザイン
データベースを用いた薬剤疫学研究において、治療経験のない患者だけを対象とするnew user designがよく利用されてきました。この手法は内的妥当性は高いのですが、研究対象患者数が少なくなりすぎるという問題点も抱えています。特に既に長く使われてきた薬剤が存在し、新薬の利用者は古い薬剤からの切り替えであるときに、この問題に直面します。この課題に対応するためにnew user designのバリエーションとして、prevalent new user design3)という手法が開発されました。
Sentinel Initiativeでは、new user designを中心とした研究デザインについてもフレームワークの確立に向けて研究を行っています。
交絡調整方法の改善
実診療では患者の臨床状態(重症度やリスク因子)によって治療法が選択されるため、データベースを用いた観察研究においては交絡の調整が大切です。
自然言語処理を用いた自動的な特徴量生成に加えて、Super Learner4)やTargeted Maximum Likelihood Estimation(TMLE)5)などの高度な統計・機械学習アプローチを組み合わせて、電子カルテベースの変数から交絡調整を改善する方法が研究開発されています。
※交絡については、以前の記事「観察研究でみられるバイアスの事例紹介」「薬剤疫学研究における交絡の対処法」もご覧ください。
最後に
FDAの医薬品安全監視活動のロードマップでは、疫学手法の研究や評価も含まれています。疫学を制度やプロジェクトに組み込み、またその最先端を自ら切り開いて仕組み化(フレームワーク化)しようという気概も感じました。
一般的に研究と社会実装の間には、大きなギャップが存在します。しかし本記事で言及された自然言語処理技術や研究手法は、社会での実装に向けた目的とロードマップが明確に描かれており、研究者にとってもやりがいのあるトピックだと思います。
引用
- Broadening the reach of the FDA Sentinel system: A roadmap for integrating electronic health record data in a causal analysis framework. NPJ Digit Med. 2021 Dec 20;4(1):170
https://www.nature.com/articles/s41746-021-00542-0 - Homepage | Sentinel Initiative
https://www.sentinelinitiative.org/ - Prevalent new-user cohort designs for comparative drug effect studies by time-conditional propensity scores Pharmacoepidemiol Drug Saf. 2017 Apr;26(4):459-468.
https://doi.org/10.1002/pds.4107 - Using super learner prediction modeling to improve high-dimensional propensity score estimation. Epidemiology. 2018; 29; 96-106
https://doi.org/10.1097/EDE.0000000000000762 - Targeted maximum likelihood estimation in safety analysis. J Clin Epidemiol. 2013; 66; S91–S98
https://doi.org/10.1016/j.jclinepi.2013.02.017

